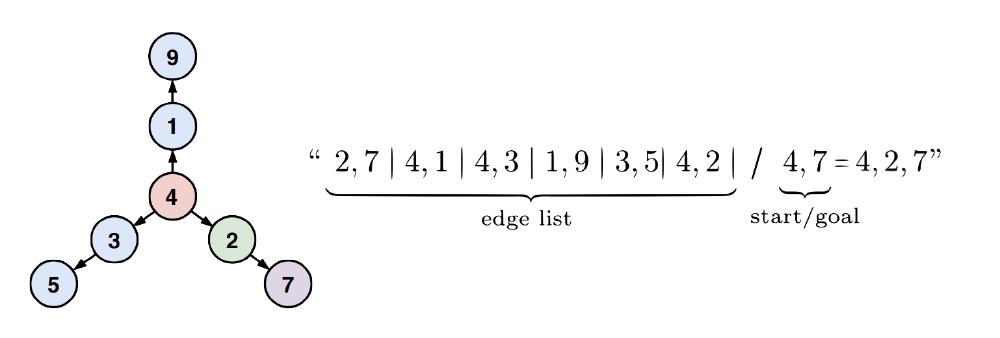
A few months ago I came upon a paper by Bachmann and Nagarajan1 that studies a failure mode in next-token prediction. They devise a toy problem where the input contains the edge list of a star graph followed by a goal node, and the target output is a path from root to goal. The model is supervised on the tokens after the equal sign.
What makes this problem interesting is the appearance of a “Clever Hans” phenomenon, named after a horse trained to perform arithmetic that actually learned to read its owner’s face2. The model learns the wrong algorithm yet still makes significant progress toward the objective through shortcuts.
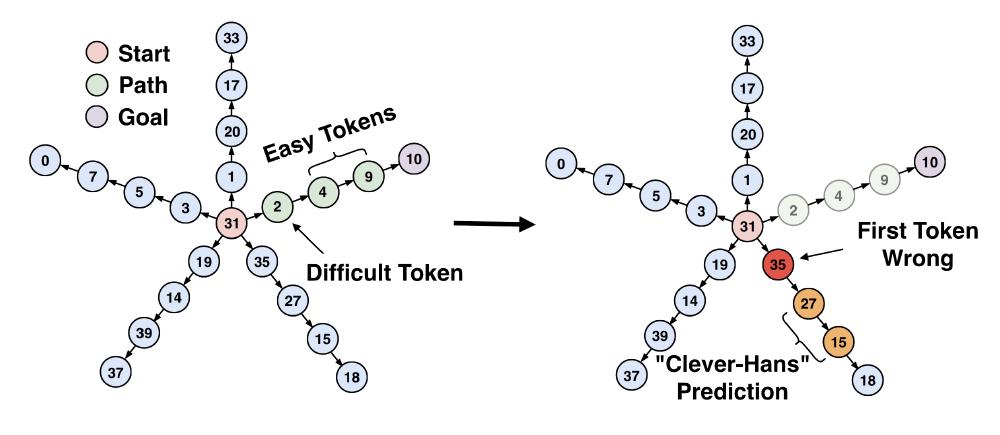
In star graphs, an auto-regressive model can learn an induction head that takes a node as input and returns its child from the edge list. This works for all nodes except the one following the root (the “Difficult Token”) because the induction head cannot disambiguate between multiple edges sharing the same parent node. Yet for long paths the loss still decreases significantly since the model successfully predicts all remaining tokens. Once this shortcut is learned, the model fails to learn the correct algorithm, which involves backtracking from the goal node to the root to identify the correct branch.
An intuitive reason for Clever Hans is that there is simply too little signal to learn a better algorithm. Each sample has only one instance of the difficult token, so the batch size needed for learning is likely very large. The star graph problem thus exposes a shortcoming of next-token prediction: teacher-forcing produces a model good at single-token predictions but not necessarily capable past that.
I suspect Clever Hans effects that manifest during LLM pre-training are somewhat alleviated in post-training when RL is applied. However, a recent paper from Dimitris Papailiopoulos’s lab identified that reasoning models loop when faced with difficult problems, taking the same path multiple times even after failing3. This can be viewed as Clever Hans at the scale of sentences rather than single tokens, where the model uses a shortcut of rephrasing itself rather than progressing towards the goal. This can be mitigated by increasing the sampling temperature, which encourages exploration.